
Data Cleaning Best Practices That Actually Work
Every intelligent business decision is based on data. Raw data is, however, seldom clean. It frequently comes dismantled, piece after piece, and in fragments. Omitting the cleaning step may falsify your analysis. Consider it the same as cooking- you would not want to make a good meal out of rotting food. The same applies to data.
This article will take you through the best practices of cleaning and preparation of your data to ensure that your data is working in your favor as opposed to working against you. The Reason Data Cleaning and Preparation is More Important Than You Think.
The majority of data projects fail due to insufficient strategy and poor models. Their failure is because the data that drives such models is messy. Research indicates that data scientists use almost 60 to 80 percent of their time merely cleaning data. Everything tells you in that number.
Data cleaning refers to repairing or deleting errors, corrupted data, duplicate data, or incomplete data. Data preparation is based on that, developing the prepared data into a machine-learning or analysis-ready format. Collectively, they constitute the basis of any credible data project.

1. You should always begin with your data source
You should go and ask yourself where the data originated before you take a single row. Is the source reliable? Is it updated regularly? An unsteady source gives unsteady results, however well you have your tools. Knowing your source will allow you to identify issues in advance and inform you of the mistakes to anticipate. Forms that are filled manually are more prone to typing mistakes and discrepancies as compared to automated systems.
Read more Gig Economy 101: How to Start a Profitable Side Hustle and Boost Your Income
2. Get Familiar with Your Data Structure
Exploring your data before cleaning. Check tables, fields, data types, and associations. This is a step that is usually hurried, but it saves hundreds of hours of headache. Inquire what every column is, verify the text values in numeric fields, and find the occurrence of dates that are represented as simple strings. Understanding your building is knowing your building in and out so that you can stop problems before they escalate.
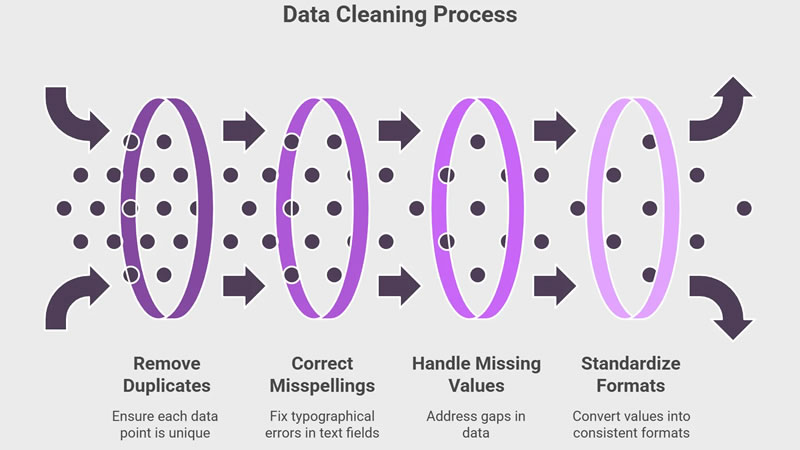
3. Missing Data: How to Do It
Lack of data is a widespread issue. It should not be ignored, but it should be remedied according to the extent of the missing and the reason. In case the number of missing values is relatively small, then drop the rows. When there are numerous values not present, fill them in with the mean, median, or a value that is likely to occur. Through appropriate handling, analysis is accurate and the results trustworthy.
4. Remove Duplicate Records
Duplicates overstate numbers, distort averages, and overstate patterns. A customer who comes thrice does not imply three customers. There is no compromise in terms of eliminating duplicates. Identify and remove duplicate rows fast with tools such as Pandas in Python. Always look at the strict duplicates and the one close to duplicates in which there is a variation in names or IDs that point to the same record.
5. Normalise and Standardise Your Data
Lack of uniformity kills information. DD -MM -YYYY in one column and MM/DD/YYYY in another column. Some spell a country as USA, and those that spell it United States. With standardisation, all values are brought to a uniform format. Normalisation of numeric values of a scale into a similar range. These two are very important steps in merging the data or training the machine-learning models.
Read more AI and Precision Medicine: Future of Personalized Health
6. Clean Your String Data
Text data is messy by nature. There is noise with the use of additional spaces, capitalization irregularities, and special characters. As an example, John Doe and John Doe look the same to a human being, but they look different to a computer. Clean up space, correct capitalization, and eliminate undesired characters. Constant strings enable your analysis to be true to reality.
7. Engineer the functions of what you already possess
After cleaning up your data, develop on it. The method of feature engineering involves the creation of new variables that are useful based on the previous ones. As an illustration, in an out-of-date column, you can get the day of the week, month, or holiday flag. This can be more effective than the model itself, in most cases. Data preparation is good in that it involves repairing issues and discovering the value concealed.
8. Categorical Variables must be encoded
The majority of the ML algorithms can only handle numbers. Unless your data is in the form of numbers, such as the color or type of product or the name of a country, then you need to change them to numbers. Some of the common approaches are label encoding, assigning a number to each type, and one-hot encoding, where a separate binary column is generated.
9. Clean and Prepare Data with the Right Tools
It is not viable to do all this manually. Effective tools make the cleaning process fast and minimize the error rate. The most popular Python library used in data manipulation is pandas. OpenRefine is efficient in cleaning dirty, unstructured data. In the case of larger pipelines, ETL software such as Talend or Apache NiFi is used to automate the whole integration. Select the right pick tools according to the size and complexity of your project.
Read more Manufacturing Robots: Complete Guide & Benefits
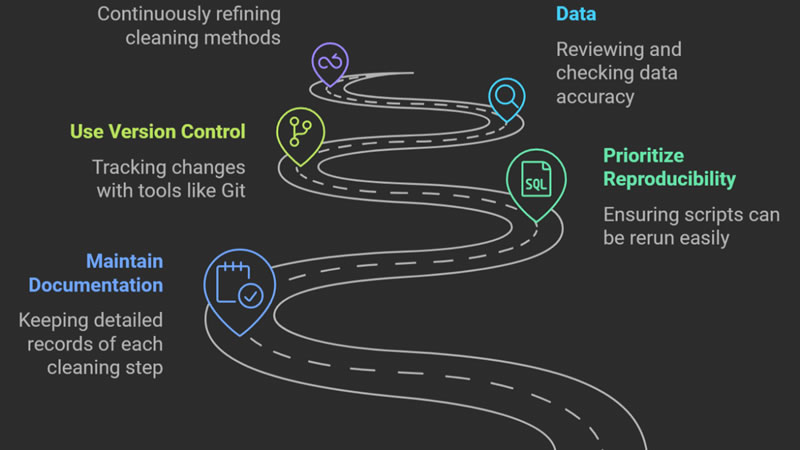
10. Document Every Step You Take
You can never rely on what you have put together without being able to trace what you did. Develop a data dictionary covering the description of every field and its possible values. Have a change log that documents all the transformations? Manage code version and data version with the help of Git or other version control systems. Through good documentation, a single-time task becomes repeatable, scalable, and smoother team working becomes easier.
Putting It All Together
Data cleaning and preparation may not be glamorous, but these activities are essential. Every superb analysis, precise model, and clever business judgment begins with clear information that has been prepared appropriately. Effort at this stage will be rewarded in the rest of the project.
Start with your source, get to know its structure, fix what may be wrong, and mould the rest of the data into something useful. That is the formula. It is not that complex; it only takes discipline and a proper approach.
Read more Mind-Blowing Scientific Discoveries of All Time
What is the distinction between data cleaning and data preparation?
Data cleaning corrects mistakes, eliminates duplications, and handles gaps. Another step that follows data preparation is the transformation and organization of data to be analyzed or modeled. Cleaning belongs to the bigger preparation process.
What is the length of time required to clean data?
It is based on the size and quality of the dataset. Cleaning in most projects can take up 60-80 percent of the overall time. To minimize this, it is possible to start with credible sources and use the same method of cleaning over time.
Which are the most useful data cleaning and data preparation tools?
The most popular cleaning tool is Panda in Python. OpenRefine is effective with sloppy text. Talend and Apache NiFi are good options in case of automated pipelines and large-scale workflows.
What is the importance of eliminating duplicate records?
Duplicates falsify statistics and average distortion. Their elimination would make the dataset closer to the real world, which would result in more accurate analysis and authentic trends.
What is feature engineering, and what is its significance?
Feature engineering generates new variables by using the available data to enhance the model accuracy. It is common in cases where better features are used, and better predictions are obtained without necessarily altering the model. It is among the most expensive steps in the data preparation.

